How we Built an AI Autorouter for Web3

David Liu

If you've built anything in Web3, you know this infrastructure pain well: RPC and API provider roulette.
Every developer we talk to has the same war stories. Providers going down during market spikes. Rate limits kicking in at the worst possible moment. Latency spikes when half of DeFi decides to hammer the same nodes.
The result? Teams spend more cycles managing infrastructure than shipping features. Manual failover systems. Fragile routing logic. Users experiencing downtime that shouldn't exist in 2025.
That's why we decided to tackle this problem and built Uniblock Autoroute, something we think fundamentally changes how Web3 infrastructure should work.
The Problem Was Deeper Than We Thought
Initially, we thought we just needed a simple load balancer. Route requests across a few providers, add some basic failover logic, call it a day. But as we dove deeper, we realized that Web3 has some unique challenges that generic solutions can't handle.
First, not all RPC and API methods are created equal. eth_call might be blazing fast on Provider A but eth_getLogs could take 10x longer. Provider B might have great archive node performance but higher latency for recent blocks. These providers aren't just different servers – they're fundamentally different implementations with different strengths.
Second, the cost structures are all over the place. Some providers charge per request, others per compute unit, some have different pricing for different method types. A naive load balancer would just distribute traffic evenly, potentially sending expensive archive queries to the most expensive provider.
Third, failure modes in Web3 are weird. Rate limiting isn't binary – it's contextual based on method type, request complexity, and your usage patterns. Geographic routing matters more than in traditional web apps because node sync states can vary by region.
We realized we weren't just building a load balancer – we were building a smart routing layer that understands the nuances of the Web3 stack.
Building a Scoring System That Actually Works
The heart of Autoroute is the data we learned from. We collect three core metrics across all our providers:
- Latency: How fast each provider takes to deliver us a proper result
- Reliability: Success rates, how many times a provider errors out, or returns an unexpected result
- Cost: Normalized across different pricing models
But here's the thing – we don't just average these scores. We use different weights based on what developers actually care about:
# Here is an example of how a simple scoring system could look like:
.png)
The EWMA smoothing was crucial. Without it, we were bouncing between providers too aggressively, which actually hurt performance. Sometimes the "optimal" provider on paper would get overloaded because everyone was routing to it simultaneously. EWMA gives more weight to recent performance while still respecting historical trends, allowing scores to adjust smoothly instead of oscillating wildly.
We also built method-specific scoring. eth_getLogs with a wide block range behave completely differently than eth_blockNumber, so we track and route them separately.
Four Profiles for Four Different Worlds
Early on, we realized that "optimal" means different things to different applications. A high-frequency trading bot cares about latency above everything else. A cost-conscious DeFi analytics dashboard might prefer slower but cheaper providers. An enterprise wallet needs rock-solid reliability.
So we built four distinct routing profiles:
- Balanced: Equal weighting across all metrics – good default for most apps
- Cost-Optimized: Prioritizes cost efficiency – perfect for data analytics and archival queries
- Reliability-Focused: Emphasizes uptime and consistency – mission-critical applications that can't afford downtime
- Latency-Sensitive: Optimizes for speed – trading bots, real-time games, user-facing applications
The beauty is that developers can switch between profiles with a simple API parameter, or even use different profiles for different endpoints within the same application.
The Architecture That Keeps Us Up at Night (In a Good Way)
Our current system processes millions of data points in real time to keep provider rankings fresh:
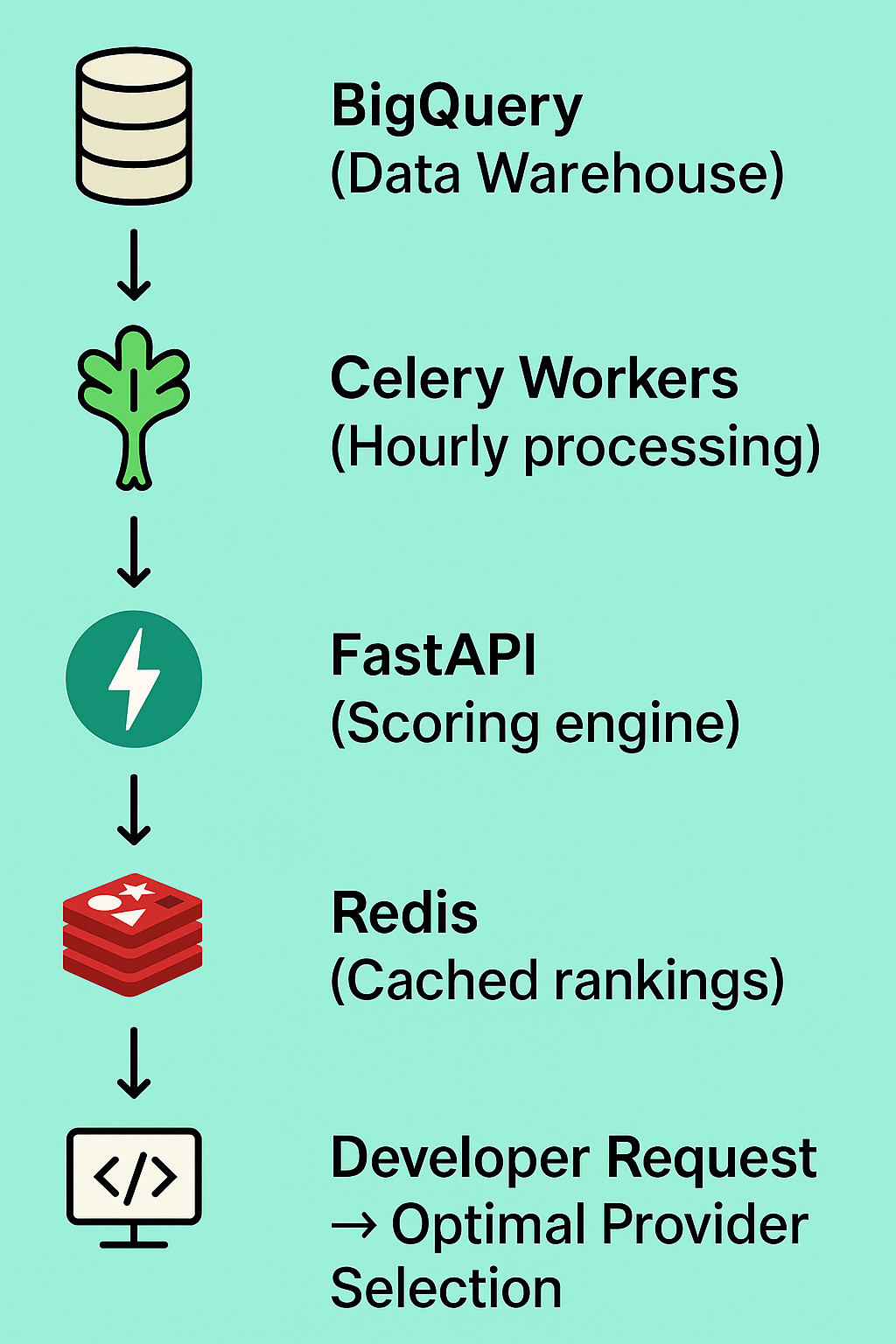
The tricky part was making this system resilient. If our scoring engine goes down, we fall back to static rankings. If a provider's performance tanks suddenly, we detect it within minutes and start routing around it.
We also had to solve the cold start problem. When a new provider comes online or a new RPC method gets added, we don't have historical data. Our system uses a conservative scoring approach and gradually builds confidence as data comes in.
Why we think our autorouter is important
Look, we've all seen "AI-powered" load balancers and "smart" routing solutions. Most of them are just marketing fluff around basic health checks and round-robin distribution.
What makes our autorouter different - and why we’re investing in it - is the combination of:
- Method-specific routing intelligence – Understanding that eth_call and eth_getLogs are fundamentally different workloads. Different methods function differently on different chains.
- Cost-aware routing – Factoring in the economic realities of different providers
- Profile-based optimization – Letting developers choose their tradeoffs explicitly
- Real-time provider scoring – Using actual performance data, not just uptime pings
The approach specifically covers our weighted scoring algorithms, the profile-based routing logic, and the method-specific optimization system. It's not just a load balancer – it's infrastructure intelligence built specifically for the Web3 stack.
The Challenges We're Still Solving
Building Autoroute taught us that Web3 infrastructure routing is an evolving problem. Here are some challenges we're actively working on:
- Geographic Routing: Performance and reliability of providers vary between different locations, we're continuing to build location-aware routing that factors in both network latency and sync freshness.
- Predictive Scaling: We can see traffic patterns before they hit providers. Our next version will preemptively route traffic away from providers that are about to hit capacity.
- Rate Limit Intelligence: Different providers have different rate limiting strategies. We're building a system that learns each provider's limits and routes accordingly, preventing rate limit errors before they happen.
- Additional Parameters: Continuing to upgrade our models to take into consideration more endpoint parameters, to allow for even more possibilities of routing based on our users' requests.
What This Means for Web3 Development
We think our autorouter represents a shift toward infrastructure abstraction in Web3. Instead of developers spending cycles managing provider relationships and writing custom routing logic, they can focus on building their actual applications.
More importantly, it levels the playing field. A solo developer building a DeFi dashboard can get the same sophisticated infrastructure routing that a major protocol uses, without the engineering overhead.
The single API key model also simplifies a lot of operational complexity. No more juggling multiple provider relationships, comparing pricing models, or building custom failover systems.
What's Next
We're already working on the next generation of features:
- Continued improvements on our ML: Further improvements to our ML models to better predict provider performance issues before they impact applications.
- Advanced Analytics: Giving developers deep insights into their infrastructure usage and optimization opportunities
- Smart Contract Integration: Direct routing decisions based on on-chain conditions and gas prices
If you want to dig deeper into the technical details, check out our developer docs or feel free to reach out. And if you're dealing with similar infrastructure routing challenges, Uniblock Autoroute is available now – get started with a free API key at uniblock.dev.

.png)



