Why RPCs Fail in Production

David Liu
.png)
Most teams treat RPCs as a solved problem, assuming reliability comes for free with popular endpoints and retries. However, this assumption often breaks down under real user traffic. RPC failures are not edge cases but a predictable outcome of blockchain infrastructure behavior at scale.
This document explores the common failure modes of RPCs in production, why common fixes only partially work, and what reliable teams optimize for to build stable systems.
What an RPC is (briefly)
At a high level, a Remote Procedure Call (RPC) is the mechanism by which applications read blockchain state and submit transactions. It acts as an intermediary between your users and the blockchain network.
However, in production, an RPC is more than just a simple interface; it's a shared, stateful, rate-limited system that must handle bursty traffic, unpredictable workloads, and potential adversarial behavior.
Where theory diverges from production
Most documentation assumes ideal conditions:
- Requests are evenly distributed.
- Latency is stable.
- Capacity scales linearly.
- Errors are rare.
These assumptions rarely hold true once real users start interacting with the system. Real traffic is spiky, with wallets refreshing aggressively, indexers backfilling data, and bots polling constantly. A single popular event can cause load to increase by an order of magnitude within minutes.
RPCs are often the first point of failure under such stress.
Common RPC failure modes
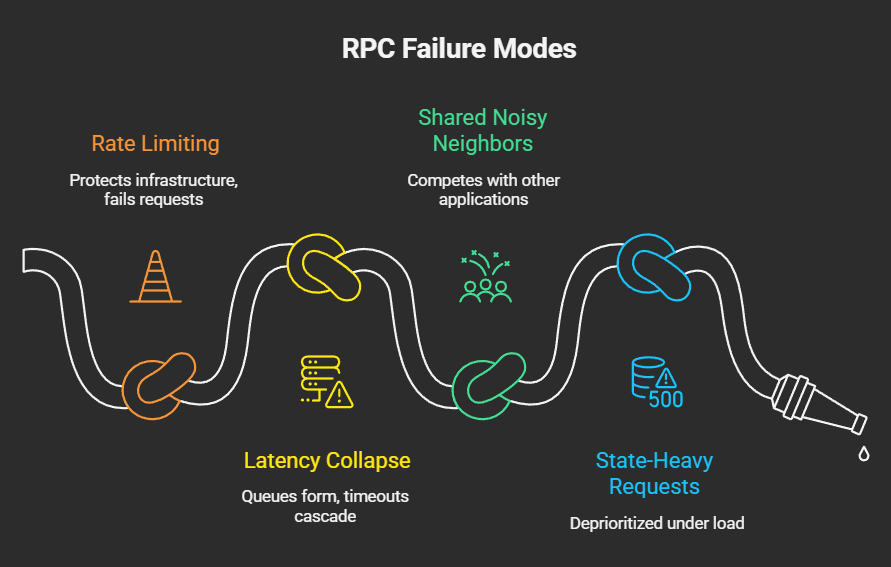
1. Rate limiting
Rate limits are not just a pricing mechanism; they serve as a safety valve to protect the infrastructure. When rate limits are exceeded:
- Requests fail quickly.
- Retries amplify the load.
- User-facing actions stall.
From the application's perspective, this manifests as random unreliability. From the infrastructure's perspective, it's a necessary measure for self-preservation.
2. Latency collapse under load
Latency doesn't degrade smoothly. Once CPU, memory, or I/O usage crosses a critical threshold:
- Queues form.
- Timeouts cascade.
- Tail latency explodes.
Applications often focus on average latency, but users experience the tail latency, which can be significantly worse.
3. Shared noisy neighbors
Most managed RPCs operate as multi-tenant systems. Your application competes with:
- Other applications.
- Indexers.
- Arbitrage bots.
- Wallet infrastructure.
Even if your application's traffic is well-behaved, you can be affected by the volatility of other tenants.
4. State-heavy requests
Not all RPC calls are created equal. Calls that:
- Traverse large amounts of state.
- Touch historical data.
- Execute complex traces.
…are significantly more expensive. Under load, providers often deprioritize or throttle these types of requests first.
Why common fixes only partially work
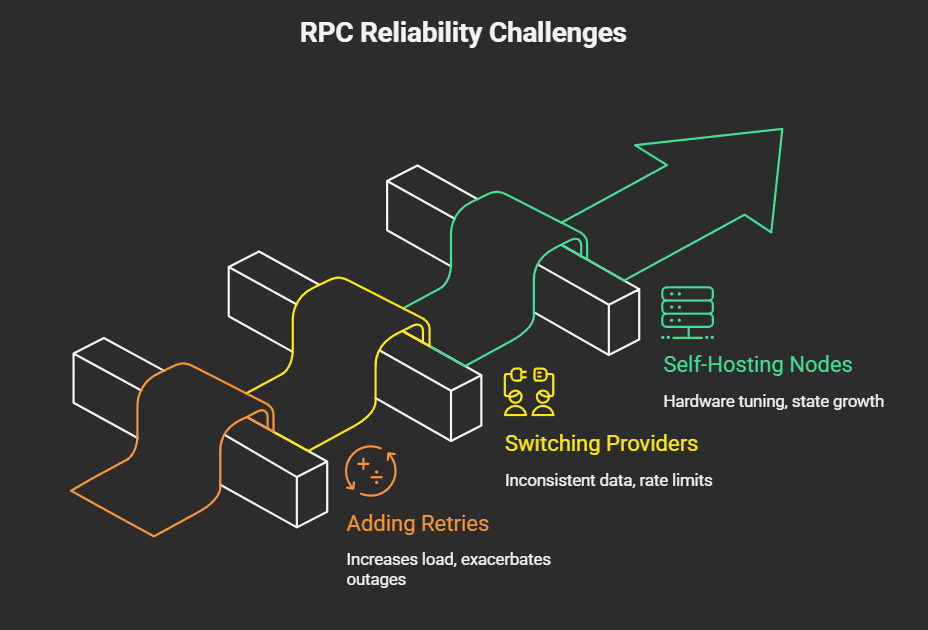
Adding retries
Retries are often the first line of defense, but they assume that failures are transient. In practice:
- Retries increase the load on the system.
- Increased load leads to higher failure rates.
- The system can enter a negative feedback loop.
Retries without proper backoff and coordination can exacerbate outages.
Switching providers
Switching to a different provider can improve availability, but it introduces new challenges:
- Inconsistent data across providers.
- Different rate limits.
- Divergent performance characteristics.
Failover without careful traffic shaping can simply shift the problem from one provider to another.
Self-hosting nodes
Running your own node gives you more control but adds significant operational overhead. Teams often underestimate:
- Hardware tuning requirements.
- The rate of state growth.
- The potential for client bugs.
- The need for ongoing maintenance.
Self-hosting replaces external unreliability with internal operational burden.
The underlying constraint
RPC reliability is fundamentally limited by physics and economics:
- Blockchain state is large and growing.
- Execution is computationally expensive.
- Demand is bursty and unpredictable.
- Supply (of resources) is finite.
These constraints cannot be overcome with better SDKs or dashboards alone.
What reliable teams actually optimize for
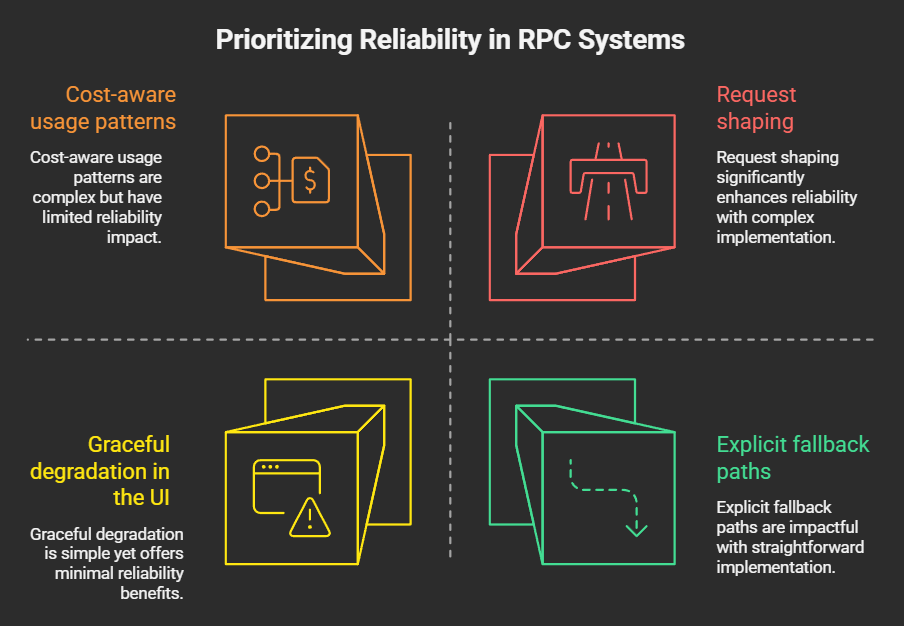
Teams that consistently ship stable systems prioritize:
- Request shaping, not raw volume: Controlling the rate and type of requests sent to the RPC.
- Observability over assumptions: Monitoring key metrics to understand system behavior and identify bottlenecks.
- Explicit fallback paths: Having alternative strategies for handling failures, such as caching or degraded functionality.
- Graceful degradation in the UI: Providing a user experience that remains functional even when the RPC is experiencing issues.
- Cost-aware usage patterns: Understanding the cost implications of different RPC calls and optimizing accordingly.
Reliability is an emergent property of system design, not simply a matter of provider choice.
Why we built Uniblock
We saw teams lose weeks chasing phantom bugs that were really RPC failures. The problem was not missing features. It was a lack of control over how traffic hit infrastructure.
Uniblock exists to make RPC behavior predictable under real-world conditions, so application teams can focus on product instead of firefighting.
Takeaway
RPCs are not just simple endpoints; they are complex production systems with inherent limits, trade-offs, and failure modes. Understanding these aspects early in the development process allows teams to ship faster, debug less, and avoid scaling surprises.
Ignoring these realities works until real users arrive, at which point the consequences can be severe.
.png)




